Distant Reading
When Brandon was entering graduate school, an older student once summed up one of life's problems as a sort of equation:
There is an infinite of material that one could read.
There is a finite amount of time that you can spend reading.
The lesson was that there are limits to the amount of material that even the most voracious reader can take in. One's eyes can only move so quickly, one's mind only process so much. This might sound depressing, as if you're playing a losing game. But it can also be freeing: if you cannot read everything, why feel the need to try to do so? Instead, read what you can with care.
Computers flip the problem: their problem is not so much with quantity of reading as it is quality. As we have discussed before, computers cannot read with any particular nuance or understanding of what they are ingesting. Instead, technology might be best suited for helping us read at scale. Critics like Franco Moretti refer to this kind of analysis, when we use technology to get a bird's eye view of a corpus, as distant reading. If close reading, which we talked about earlier, gives careful attention to every word in a text, distant reading assumes that we can get new insight from thinking more broadly, by using computers to take in more texts than would otherwise be possible. Thus, we might have a computer give us schematic representations of thousands or even hundreds of thousands of texts. In the last chapter, we worked with stopwords and frequency analyses. We were mostly interested in the numbers of times that particular words appeared over the course of our corpus. Computers are especially good at reading for things just like this. On our own, we would never be able to read all 19th century British novels. But computers can help us to at least get some sense of this great body of work. Reading at such a great scale can also offer us a chance to chip away at what Margaret Cohen has called the "great unread", all that writing that has gone unnoticed because it never became part of the literary canon.
It might appear as though distant reading is less critical: after all, you could theoretically construct a beautiful program to analyze thousands of books for you without you having to ever crack open a single one of them. And some people do. As Matt Jockers, Ryan Cordell, and others have argued, however, even reading at this macro level requires attention to micro detail. Those same skills you were practicing with close reading earlier in the book? They are still deeply relevant. The work only begins once you have some results and a graph. You then have to figure out what elements are meaningful and what they might indicate. And the exploration very often takes you back to particular parts of the corpus that you want to read in more detail.
Patterns
One way to begin thinking about developing approaches to using tools and methods like these is to take a step back. When looking at the results of distant reading, you are, more than anything else, looking for patterns and outliers. You could ask yourself a number of questions when looking at the results of tools like Voyant.
- Does anything clearly not belong or not make sense?
- What surprises you?
If you know your text is about the American South, and you find that the fourth most common token is 'France,' that probably says something interesting. You might need to revise your expectations and your research questions, and that is perfectly fine. This is actually part of the research process; if you don't revise your analysis, that means you aren't responding to what you are encountering in your sources. The most interesting thing about a project is rarely the first thing we think it will be.
- How do the numbers that the tool spits out at you connect with underlying concepts in the text?
Our reading experience, our interpretations of a text, the way it makes us feel: these are the result of may things, but language plays a role in constructing all of them. Words form the basis for everything we get out of reading, so we can work backwards from word to concept. Think about what underlying concepts might be taking shape as a result of particular words. For example, if four of the top five words in a text are male names or male pronouns, that might say something about gender representation in the text. Personal pronouns might say something about what it means to be a self in your text. Four times more exclamation points than periods? That might say something about the rhetorical impression the author wants to convey.
- What trends do you see in the data?
- Is anything clearly decreasing or increasing over time?
- Are things largely the same over time?
If you have a corpus where the dates for each text are known, you can begin to draw inferences based around language use over time. The Google NGram tool is built on such assumptions, though you should take care to think about how changes in language itself might affect your results (the classic example of this is the long s, which computers frequently read as an 'f' in older texts). The trends you see can offer good opportunities to reflect on your own understanding of what happens historically over the same time period. Alternatively, since we experience individual texts over time, we can examine how the use of a concept or word changes from the beginning of a text to the end. All of this might offer a way into thinking about the text as a whole.
- Does something just look plain wrong?
It is easy to think that the results the computer gives you are correct, and to take them at their word. After all, how could numbers lie? The truth is, however, that any data is the result of the biases of the people who produced them. Seemingly good statistics can make anything seem like objective truth when there might not be anything more than a pretty picture:
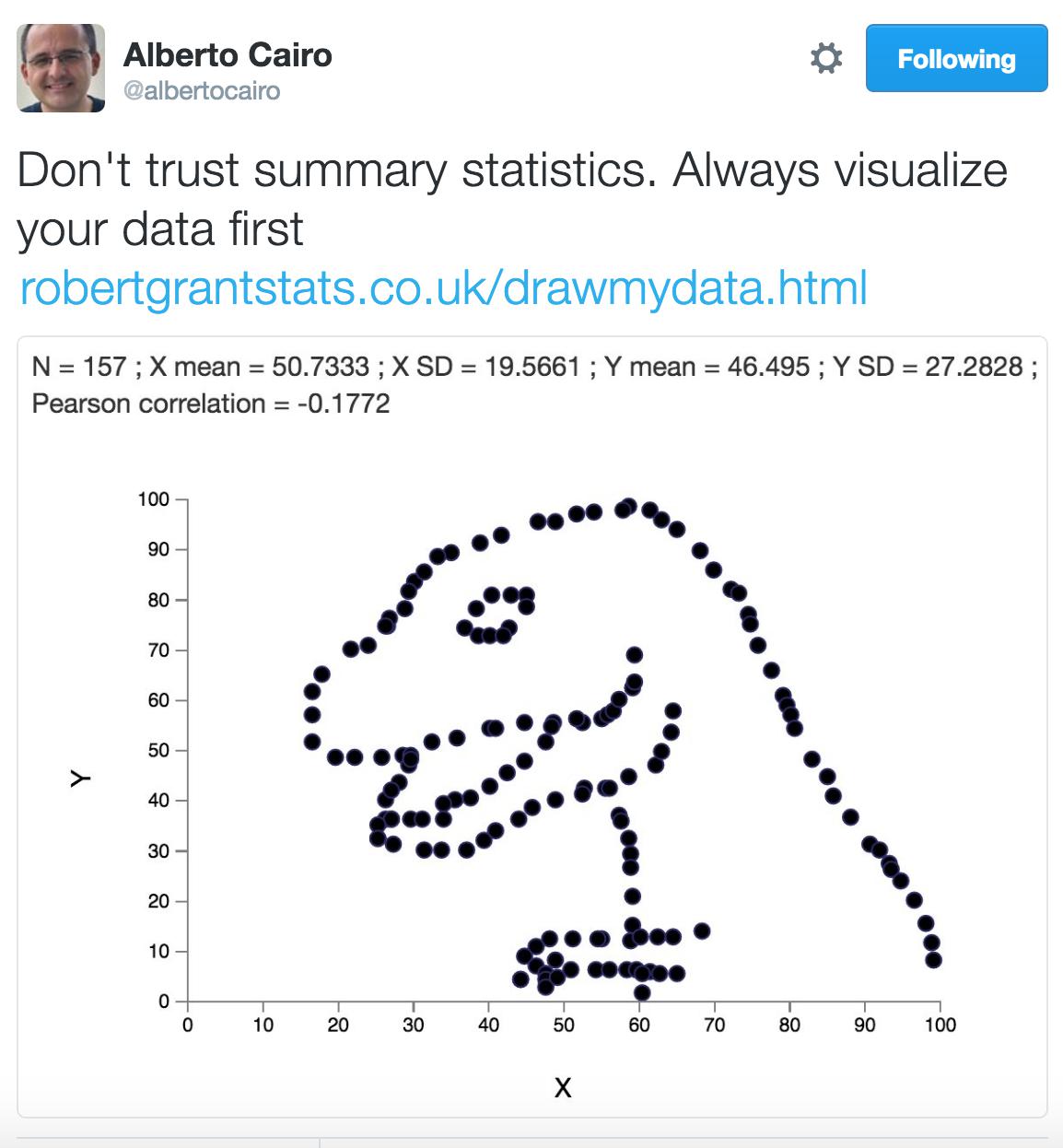
And a flashy visualization can just as easily show nothing.
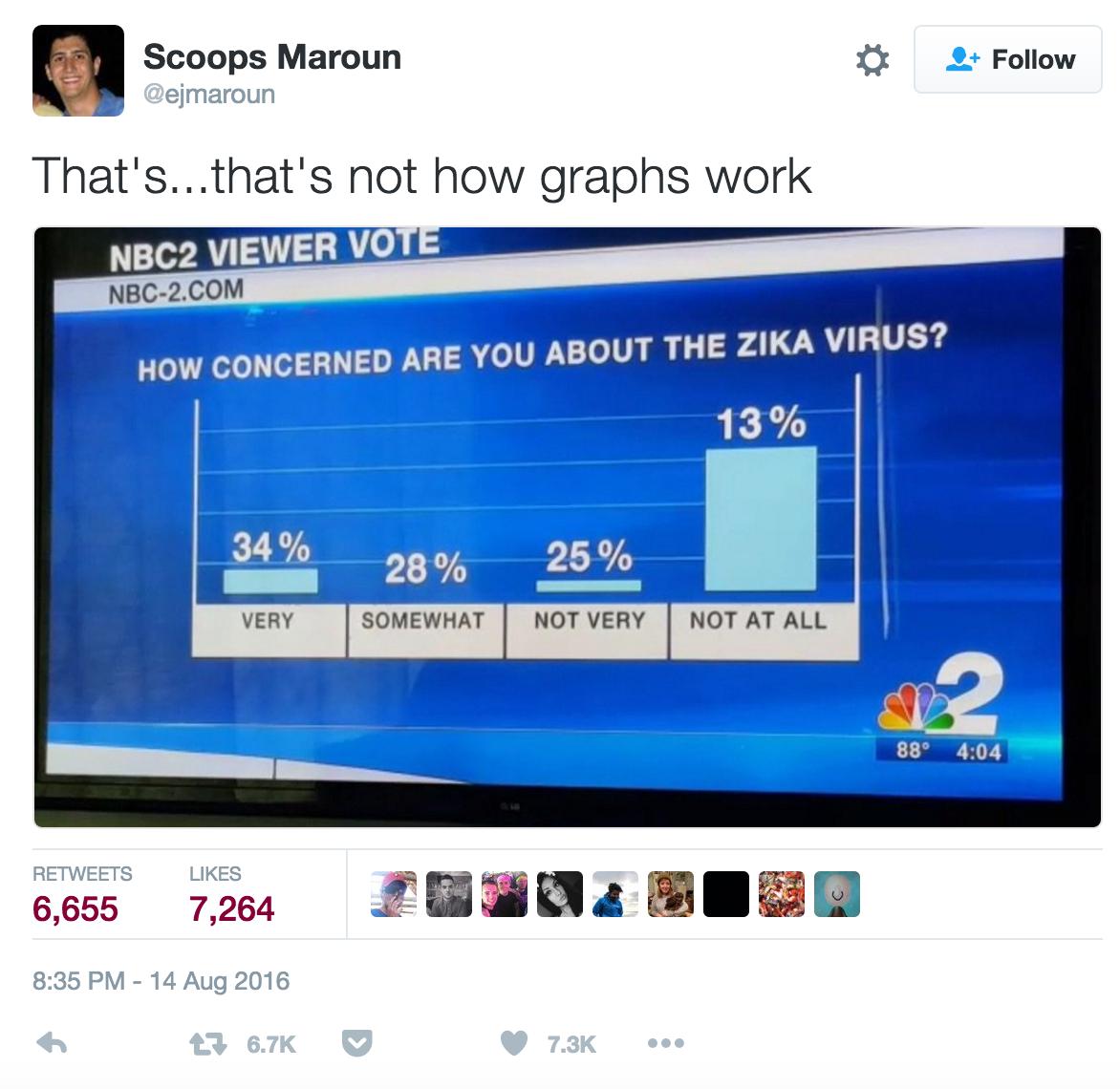
Your own results might be the result of some setting that you have configured just slightly incorrectly. Or maybe you uploaded the wrong text. Or maybe you are misunderstanding how the tool works in the first place. If something has you scratching your head, take a step back and see if there is something wrong with your setup.
But wait, you say, I don't know enough about X to be able to do this kind of work!
You're fine! You don't need to know anything about statistics or computer science in order to be able to say something meaningful about texts through distant reading. Knowledge about both of these fields can go a long way and give you more meaningful and interesting things to say, but these tools, methods, and ideas should not be beyond anyone. Take a tool out for a spin and see what happens. You can always learn more about these fields to help give your analysis a stronger foundation, but it will all be for nothing if you don't even try because of such anxieties. Play first. Then enrich your work with further study.
You cannot read everything. Instead, focus on what humans are good at: reading with care and offering interpretations. The computer can work with big numbers much quicker than you. Your job is to help it do so in a meaningful way.
Further Reading
- Ryan Cordell provides a helpful examination of the interconnectedness of close and distant reading in "Scale as Deformance"
In addition, the following resources offer great introductions to distant reading.:
- Franco Moretti, Graphs, Maps, Trees: Abstract Models for Literary History.
- Margaret Cohen, The Sentimental Education of the Novel.
- Matt Jockers, Macroanalysis.